Easy-to-use text-to-speech
Adventure games, the genre I like, tend to contain a lot of talking. Apart from writing the character statements on the screen, bigger game studios hire voice actors to record them and play the recordings. It is a lengthy and costly process. I decided to see how far text-to-speech is from being able to substitute human actors for indie adventure games.
Problem definition
I define the text-to-speech problem as:
- take as input a short English text prepared by the game writer and one of a couple of identities of the game characters
- produce an audio wave where a character speaks the text.
Text-to-speech is an active research domain, and one could easily spend weeks (or a whole career) looking for the best solution. I chose to limit myself to methods that:
- are available for free,
- don’t require me to do further research to make it work,
- are easily available on the internet; in particular require no training neural networks on a high-end GPU for days.
High-level state of research
To explain how the current models work, one needs to first define what a mel-spectrogram is.
According to Wikipedia:
Mel-frequency cepstrum (MFC) is a representation of the short-term power spectrum of a sound, based on a linear cosine transform of a log power spectrum on a nonlinear mel scale of frequency.
Putting it in English, mel-spectrogram describes how much energy the part of the sound wave of a given frequency transports in time.
It’s a three-dimensional plot: the color conveys the amount of energy (lighter color: more energy), the Y-axis corresponds to frequency, and the X-axis to time.
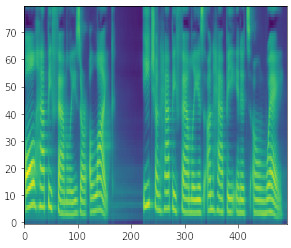
An important property of mel-spectrograms is that they contain less information than the initial sound wave, i.e. there are multiple waves with the same mel-spectrogram.
Current models
To generate a single sound wave from a sentence of text, people currently apply two models sequentially:
- An acoustic model, which transforms text to a mel-spectrogram, e.g. Tacotron 2, Glow-TTS, or FastSpeech 2.
- A vocoder, which maps the mel-spetrogram to the actual sound wave. The most popular vocoder is HiFi-GAN, with other examples being MelGAN and WaveGlow.
There are some end-to-end models, like WaveNet or FastSpeech 2s which are able to generate waves directly from text (without intermediate mel-spectrograms), but they don’t seem to be as popular these days.
Datasets
There are dozens of datasets of varying quality containing recorded voice and the corresponding text. After skimming the papers above, I think these are the most popular ones:
- LJ Speech: a dataset with one female English speaker, reading 13100 short audio clips from 7 non-fiction books, consisting of approximately 24 hours in total.
- LibriTTS: a multi-speaker English dataset containing 585 hours of speech by 2456 speakers (around 15min/speaker), reading Project Gutenberg books.
- VCTK: 44 hours of mostly newspaper passages, read by 109 English speakers with different accents1, so 0.5h of speech/speaker.
Analysis of the models
For the sake of this post, I tried out the three acoustic models mentioned above: Tacotron 2, Glow-TTS, FastSpeech 2, whose implementations are available on Github. I combined them with a Hifi-GAN vocoder.
Using pretrained models
While all of the papers claim they managed to train on either LJSpeech or one of VCTK and LibriTTS, for Glow-TTS and Tacotron 2 it was hard to find models pretrained on the multi-speaker datasets.
Here are the samples generated from the models based on LJSpeech:
Both GlowTTS and tacotron sound great, with Glow-TTS maybe being a bit better. Fastspeech breaks a little and has problems with semicolons.
For a game with multiple characters, I need to generate a couple of different voices. While FastSpeech’s quality was not as good as the other models’, the authors of its Github repo provided a model pretrained on VCTK with an ability to condition on a speaker.
Here are samples I generated using FastSpeech2 with two different speakers:
Not surprisingly, the voice is even more robotic2 (VCTK has more data overall, but less per speaker), but at least the model is easily accessible.
Modifying the vocoder
I mentioned on which datasets the acoustic models above were trained, but what about the vocoder (HiFi-GAN)?
In its repo, authors provide checkpoints of HiFi-GAN trained on either: LJSpeech (in a version finetuned to the mel-spectrograms provided by Tacotron or not), VCTK, or LJSpeech, VCTK, and LibriTTS together. The last one (called universal model) was provided for easy finetuning to a particular acoustic model/another dataset.
To generate the previous samples, I used the vocoder model trained on the same dataset as acoustic model used (using the Tacotron-finetuned version for LJSpeech)3.
One may wonder: to what extent the choice of the dataset the vocoder was trained on is important? In other words: can we train a single vocoder and use it with different datasets?
Technically, the vocoder needs to choose one sound wave out of many that have the same mel-spectrogram as its input. However, it’s possible that the mel-spectrogram contains all the important information about the sound, and there is only one “reasonable” sound wave to choose, and the vocoder only needs to learn how to find it.
As the vocoder’s input is only the mel-spetrogram (no separate text), it has to include the information about what is said. Is the speaker’s identity encoded there too? If not (and it’s the vocoder that injects this information into the sound wave), we will be able to change the speaker by using a different HiFi-GAN checkpoint.
I tried doing just that: passed a mel-spectrogram generated by a model trained on LJ Speech to the vocoder trained on VCTK:
As you can hear, the original (LJ Speech) voice is still audible in the sound wave, meaning that mel-spectrogram contains speaker-specific features. At the same time, the voice is more shaken compared to when the correct checkpoint was used, meaning that the vocoder itself needs to be adjusted to the dataset, too.
Finetuning
Everything I generated so far was either using the same female voice of LJ Speech, or was noisy. As I would like to get samples with multiple voices, I decided to try finetuning (adjusting the weights of) the models.
For the extra data to finetune the models on, I used all data available for speaker 270 in VCTK. It is a male voice (so easy to distinguish from the LJ Speech one, even for an amateur like me), and there is around half an hour of it available.
Out of the models I tested above, finetuning is easily possible only for Tacotron and HiFi-GAN, as:
- Fastspeech2 comes already trained on VCTK, so I can’t expect to get anything better than what’s already there 4.
- the authors of the Glow-TTS repo provide a pretrained model for inference, but they don’t publish a part of the training model (one handling Data-dependent initialization) that is necessary for finetuning.
Tacotron
I finetuned the LJSpeech model for another 6000 steps. The validation loss was already at the lowest after 2000. As the training was taking around an hour for 1000 steps, two hours was enough to finetune Tacotron on the new speaker’s data.
Here are the samples from the model, generated with the VCTK version of Hifi-GAN:
HiFi-GAN
When Tacotron generates mel-spectrograms, it does so one timestep at a time, passing whatever was generated at the previous steps as an input for the current-step generation5.
It means if a model makes a mistake mid-sentence, it’s hard for it to get back on track. One can hear it easily early in the training when the model starts the sentence correctly but then breaks down into mumbling:
To avoid being passed “wrong” mel-spectrograms while still adapting the vocoder to the ones produced by a particular acoustic model, HiFi-GAN uses Tacotron in a “teacher-forcing” mode when it is finetuned.
This mode is a method to change the inference behavior of Tacotron. When generating the \(i\)-th slice of the mel-spectrogram, instead of conditioning the model on the previous output the model generated, it uses the ground-truth mel-spectrogram (produced out of a ground-truth sound wave) as the conditioning input.
This way, even if at some point the Tacotron model produces the wrong mel-spectrogram slice, the error will not get accumulated, as the future predictions won’t use the incorrect slice.
As such, the training data for HiFi-GAN consists of mel-spectrograms produced in the teacher-forcing mode by the already finetuned Tacotron and the sound waves. After generating it, I finetuned the vocoder using the “universal” checkpoint from the repo.
Here are samples I got without finetuning (using base universal checkpoint) HiFi-GAN (left), and after finetuning for around 10h (right).
The finetuning helped a bit, but it didn’t manage to fully remove the metallic vibration when the actor would be taking a breath.
Compute
Apart from learning the details of text-to-speech technology, this experiment was also an exercise in getting free access to the computing power.
Everyone knows that training the models on a CPU takes a long time. Furthermore, the code is written in a way that you need to modify the code to not use a GPU, which isn’t always easy.
I tried out two venues that offer free GPU for training deep learning models:
I found Colab easier to use overall: it was quicker to connect to a runtime, and the integration with Google Drive made moving data and the code between the local machine and the Colab easy.
Another benefit of Colab is that it’s more popular, so there are lots of instructions online on how to do even complex things6.
The top selling point of Paperspace is that they give a guaranteed uptime of up to 6h.
In the Colab, Google sends a pop-up to check whether you’re still there every couple of hours and disconnects you after some time anyway. In Paperspace, when you request a machine you may be asked to wait, but once you get it reserved, it’s yours for the period you requested it for.
Even more, you can close the browser window/turn off the computer and still expect the GPU to be crunching the matrices for you in the background, while the Colab disconnects you from the accelerator the moment you close the tab.
It makes Paperspace more convenient for training, as you can leave it for the night, not having to continuously monitor the process.
I also liked the interface of Paperspace a bit more, as it looked a bit more like a full VM with a disk and terminal (even though I didn’t manage to make tensorboard work), but that’s a minor difference.
Overall, I would say that Colab is better for doing quick inference, and Paperspace would be my choice for finetuning models. Full training (which would take around a week for the models I tested) would still be painful to do in 6h increments, but I didn’t want to do it anyway.
Prosodies
If you hear a couple of sample sentences generated by these models, you’ll likely find them correctly pronounced but lifeless. The intonation, accent, and rhythm that conveys emotions (called prosody by the linguists) are not there.
One could claim that understanding the text enough to express prosody is an insanely difficult problem, but I don’t think it’s crazy to expect it to be solved anytime soon. It sounds easier than the type of things GPT-3 does, although GPT-3 is an effort bigger by orders of magnitude (in terms of parameters, people, compute, etc.) than any of the models described above.
I haven’t seen TTS expressing emotion yet, though. I found one paper that goes in the direction of controlling the prosody with some good samples, but unfortunately without available code.
The significant majority of the speakers come from the British Isles.↩︎
quite appropriately to be fair, given that it’s generated by a machine↩︎
For LibriTTS, even though the HiFi-GAN repo doesn’t contain the model trained only on LibriTTS, the FastSpeech2 code authors included a LibriTTS checkpoint directly in theirs.↩︎
Technically, multi-speaker training could be more difficult than finetuning on a single (new) voice. I still don’t expect anything better than the poor quality of LJ Speech, for which a lot of data is available.↩︎
the models that have this property are called autoregressive↩︎
For example, for another project, it was easy to get Colab to record video from the webcam and play it back.↩︎